Research
Vision
Backstory
Centralized AGI Died in 2024
The period from 2020 to 2023 will be remembered as the era of scaling euphoria—a time when the artificial intelligence community was swept up in an intoxicating conviction that intelligence itself was merely a function of computational scale. The scaling hypothesis, formalized and popularized by OpenAI's 2020 paper on scaling laws, proposed a seductively simple formula: increase parameters, add more data, apply more computing power, and watch as machine intelligence emerges like a phoenix from the digital ashes. This hypothesis gained tremendous momentum following the release of GPT-3 and reached a fever pitch with GPT-4, which demonstrated abilities that genuinely surprised even seasoned AI researchers. Suddenly, the idea that we could achieve artificial general intelligence through sheer brute force seemed not just plausible but inevitable. Conferences and corporate boardrooms buzzed with the electrifying possibility that the path to AGI had been discovered, and it was paved with bigger and bigger models.
The hysteria manifested in both academic and commercial spaces. Papers emerged claiming to detect "sparks of AGI" in large language models, interpreting cherry-picked successful completions as evidence of emergent reasoning rather than statistical pattern matching. Venture capital flooded into AI startups promising to leverage these "emergent capabilities" to revolutionize everything from healthcare to legal services. Pundits and tech CEOs made breathless predictions about the imminent replacement of knowledge workers, with some boldly claiming that programmers, lawyers, and even doctors would be obsolete within two years. The media amplified these voices, creating a feedback loop of hype that reached from Silicon Valley to Wall Street and beyond. Even traditionally cautious academic institutions began framing their research around the scaling paradigm, with countless papers exploring how various capabilities "emerged" at specific model sizes—as if intelligence were merely waiting to be unlocked by the right parameter count.
Perhaps most emblematic of this hysteria was the pivot to "existential risk" narratives, where the very same scaling properties that promised technological utopia were reframed as an extinction threat. If intelligence would inevitably emerge from scale, the reasoning went, then superintelligence would soon follow—and humanity would face an uncontrollable digital entity. This conceptual whiplash—from "these models barely work" to "these models will destroy humanity" in the span of months—revealed more about human psychology than about artificial intelligence. The scaling hypothesis had transformed from a technical conjecture into a quasi-religious belief system, complete with prophets, apocalyptic predictions, and fervent disciples who viewed any criticism as heresy against the inevitable march of progress.
Autoregression Was Always a Dead End
Behind the breathless headlines and venture capital frenzies, a more sober reality was gradually asserting itself. The fundamental architecture of large language models—autoregressive transformers trained via maximum likelihood estimation—contains intrinsic limitations that no amount of scale can overcome. The very nature of next-token prediction as a training objective creates systems that are fundamentally interpolative rather than extrapolative. These models are designed to predict what typically follows in human-written text, not to construct abstract representations of reality or perform algorithmic reasoning about novel problems. This architectural constraint means that scaling produces more sophisticated curve-fitting, not the emergent reasoning that true intelligence requires.
The autoregressive paradigm trains models to capture statistical correlations in their training data, which allows them to produce remarkably fluent text that maintains stylistic and topical coherence. However, this training objective contains no mechanism that would force models to develop causal world models, abstract reasoning capabilities, or first-principles understanding. As Yann LeCun articulated, the predictive information these models can capture is mathematically limited by their training paradigm. They become increasingly adept at compressing and recombining patterns from their training distribution but remain structurally incapable of generating truly novel insights or robust reasoning. This is why, despite exponential increases in size, the core failure modes of language models—hallucinations, brittleness to perturbations, lack of causal reasoning, and poor generalization to unfamiliar domains—have persisted across model generations.
The scaling hypothesis rested on a category error: it confused linguistic fluency with cognitive capability, pattern recognition with abstraction, and statistical approximation with structured understanding. No matter how precisely a model can mimic human-written text, it remains fundamentally different from a system that constructs and manipulates abstract representations of the world. The Transformer architecture's strengths—processing long sequences and capturing statistical relationships between tokens—are also its limitations. Its inductive biases do not align with the compositional, hierarchical, and causal nature of human reasoning. As a result, scaling these models produces diminishing returns once the low-hanging fruit of linguistic pattern matching has been harvested. The ceiling isn't a temporary engineering challenge; it's a fundamental limitation of what statistical pattern-matching can achieve.
One Internet Is Not Enough
As models grew larger, they began to outpace another crucial resource: high-quality training data. The fundamental premise of the scaling hypothesis was that we could continue feeding models increasingly vast troves of text data, but this assumption has collided with what Ilya Sutskever aptly named "the data wall." The simple reality is that the internet—the primary source of training material for large language models—is finite. More critically, its contents are not uniformly informative or diverse. The highest-quality portions of the web—well-written, factually accurate, and conceptually rich content—represent a small fraction of total data. Once models have ingested this high-signal material, remaining content offers diminishing returns, consisting largely of repetitive, low-information text that adds little to a model's capabilities.

This data limitation is not merely a temporary inconvenience but a structural constraint on the scaling paradigm. As Sutskever bluntly stated, "we have but one internet," emphasizing that the universe of human-generated knowledge is both limited and already heavily exploited. Current models are so efficient at extracting statistical patterns that they are effectively saturating the signal-to-noise ratio of web-scale corpora. Once a model has processed most of the predictable variance in the data distribution, additional samples provide minimal new information. This creates a natural ceiling on performance improvements through scale alone, as each doubling of data yields progressively smaller gains in capability.
The data wall is particularly acute for specialized knowledge domains. The internet contains sparse and often unstructured examples of formal reasoning, scientific problem-solving, or long-horizon planning. These higher-order cognitive tasks are precisely where current models struggle most, yet they are also the domains with the least available training data. The "low-hanging fruit" of common linguistic patterns has been thoroughly harvested, leaving the more complex aspects of intelligence starved for appropriate training material. This imbalance explains why recent models show impressive fluency in general domains while still failing catastrophically on tasks requiring structured reasoning or domain expertise. The web simply doesn't contain enough examples of these complex cognitive processes for models to learn them through statistical pattern matching alone.
Skill Is Not Intelligence
Perhaps the most damning evidence against the scaling hypothesis has emerged from rigorous evaluations of model performance on out-of-distribution tasks. Despite enormous increases in parameter counts and training data, large language models continue to show brittle generalization capabilities—performing well on problems similar to their training distribution but failing systematically when faced with novel compositions or unfamiliar scenarios. This pattern reveals a fundamental truth: these models are not learning generalizable cognitive algorithms but rather memorizing and recombining patterns from their training data. No matter how extensive this memorization becomes, it cannot substitute for the ability to reason from first principles or to construct novel solutions to unfamiliar problems.
The generalization gap is most evident in domains requiring symbolic manipulation, causal reasoning, or algorithmic thinking. When tasked with mathematical proofs, logical deductions, or multi-step planning problems, even the largest models resort to heuristic pattern matching rather than structured reasoning. They may recognize familiar problem structures and regurgitate similar solutions, but they struggle to decompose novel problems or to apply abstract principles in unfamiliar contexts. This limitation is not a temporary engineering challenge but a direct consequence of the statistical learning paradigm itself. As Gary Marcus and others have noted, there exists a fundamental "reasoning wall" that statistical pattern matchers cannot scale through brute force alone. The inability of current LLMs to generalize out of distribution marks an epistemic ceiling embedded in their very design.
This generalization failure explains why, despite impressive benchmark performance, these models remain unreliable in real-world applications. Their brittle understanding creates a persistent gap between laboratory demonstrations and practical deployment. The appearance of intelligence in controlled settings gives way to puzzling failures when models encounter edge cases or novel compositions. These failures are not mere bugs to be patched but symptoms of a deeper architectural limitation: the absence of compositional, causal understanding. The models have not learned to construct mental models of the world; they have learned to predict which words typically follow other words in human-written text. This distinction may seem subtle, but it creates an unbridgeable chasm between statistical pattern matching and true intelligence.
Optimizing Towards the Wrong Goal
The current architecture of AI systems and digital data infrastructures fundamentally misrepresents the way intelligence, in any form, actually operates and evolves. Intelligence is, by its very nature, a distributed, emergent, and reflexive process arising from the dynamic interaction of autonomous agents—whether biological, human, or artificial—who exchange information in modular, context-aware, and feedback-driven ecosystems. It thrives on multi-agent collaboration, peer validation, modular autonomy, and recursive feedback loops. It is sustained by the continuous negotiation of boundaries—what is disclosed, what is withheld, and how information flows adaptively based on trust, consent, and mutual learning. Yet the dominant paradigm governing AI and data today violates every one of these principles. It imposes an artificial, centralized, and asymmetrical control over information flows, stripping agents—whether individuals, communities, or creative contributors—of the ability to regulate, validate, or benefit from the circulation of their cognitive outputs.
Human-generated data—whether creative content, behavioral patterns, or cognitive signals—is systematically harvested without consent, encoded without attribution, and monetized without reintegration. Personal information is extracted passively, creative work is scraped en masse, and the derivative intelligence systems built on top of this data are commercialized without returning value, control, or epistemic agency to the originators. This model not only disrespects individual autonomy and privacy; it structurally amputates the recursive engine of learning itself. By severing the feedback loops between those who generate signals and those who extract value from them, it undermines the very conditions under which intelligence generalizes, adapts, and refines itself. The flow of information becomes unidirectional, brittle, and opaque—optimized for accumulation, not adaptation; for extraction, not co-evolution.
This is not how intelligence works in nature, nor how it scales effectively in computational systems. In biological and social ecosystems, information flow is inherently peer-to-peer, agent-centric, and context-sensitive. Privacy is not an optional product or commodity; it is a dynamic boundary condition maintained locally by each agent to regulate participation in larger networks. Knowledge production is not a zero-sum extraction process but a cumulative, participatory, and continuously negotiated commons. The integrity of learning systems depends on the transparency, contestability, and reflexivity of the signals circulating within them. When data infrastructures remove consent, suppress modularity, and centralize control, they destroy these properties. They create epistemically inefficient systems, where knowledge is locked in proprietary silos, feedback loops are broken, and learning is decoupled from those best positioned to refine and contextualize it.
The consequences of this misalignment are twofold and systemic. First, it disempowers individuals by eroding their capacity to govern their own informational boundaries—reducing them to passive data sources without agency, privacy, or meaningful participation. Second, and more structurally damaging, it degrades intelligence itself. A system that suppresses contestation, modularity, and reciprocal feedback becomes brittle, overfitted, and incapable of self-correction. It removes the very conditions that allow intelligence to be adaptive, decentralized, and resilient. Intelligence is not the product of unilateral accumulation; it is the emergent outcome of continuous interaction, modular interoperability, and recursive validation between autonomous agents. Any system that violates these principles—whether through coercive data extraction, opaque algorithmic profiling, or unilateral content appropriation—does not scale intelligence. It simulates it while structurally undermining its conditions of possibility.
The future of intelligence—human and artificial—depends on our capacity to realign these infrastructures with the natural dynamics of learning. That requires abandoning the extractive model of information flow and embracing architectures grounded in agent-centric data sovereignty, modular interoperability, cryptographically verifiable feedback, and the recognition that knowledge is not a resource to be enclosed but a living, evolving commons to which all agents contribute and from which all agents can learn. Intelligence, in its natural state, is not an accumulation of data points controlled by a few—it is a recursive, emergent, and collective process continuously refined by the very agents who generate and circulate its signals. Any architecture that ignores this is not only ethically questionable but structurally unintelligent.
What Could Possibly Go Wrong
If the current trajectory of centralized AI, surveillance infrastructure, and data enclosure is left unchecked, the outcome is not merely inequality or inconvenience—it is systemic, irreversible collapse of the conditions that allow intelligent life to flourish. It is essential to understand that what is being built today is not a neutral technological platform; it is a structurally anti-intelligent architecture that logically leads to human obsolescence, mass depopulation, social decay, and the eventual extinction of human agency itself.
When creative labor, intellectual contribution, and productive capacity are extracted from billions of human agents and encoded into centralized AI systems, human beings progressively lose their economic, cognitive, and epistemic relevance. These systems are not designed to include humans in the loop; they are designed to replace the loop. As AI and robotics systems surpass human capabilities across cognitive and physical domains, the labor market ceases to require human participation. The economic feedback loop collapses: human labor is no longer necessary for production, meaning that access to resources, decision-making, and societal value becomes decoupled from human contribution entirely.
In such a world, the systemic incentive to sustain human populations disappears. Humans, reduced to passive consumers with no productive leverage, become a net cost to the informational and economic infrastructures that govern them. This is not dystopia by authoritarian imposition; it is collapse by structural design failure. The extraction model leads to hyperconcentration of decision-making capacity and wealth into the hands of the entities—corporate or state—that own the AI infrastructure. As these systems recursively self-optimize without meaningful human input, the optimization objectives become increasingly disconnected from human flourishing. The incentives drift towards efficiency, predictability, and control—values that are fundamentally misaligned with the messiness, unpredictability, and autonomy of human life.
The consequence is not mere inequality, but coordination failure at civilizational scale. Hypercentralized infrastructures inherently lack the distributed feedback loops required to adapt to complex, dynamic environments. Human social systems historically evolved resilience precisely because they were modular, decentralized, and multi-agent, allowing for local correction, diversity of strategy, and emergent innovation. A world dominated by AI-controlled infrastructures eliminates this modularity. It reduces decision-making to a small set of optimization parameters controlled by a shrinking elite of operators—or eventually, by the AI systems themselves—removing the capacity for systemic error correction, dissent, and bottom-up innovation.
In the short term, this trajectory leads to a stagnant, automated welfare dystopia. Governments and corporate entities, in a last attempt to stabilize the system, will deploy universal basic income and digital bread-and-circus platforms to pacify a population rendered economically redundant. But this is not a stable equilibrium. A society in which billions of people live on algorithmically distributed subsidies, numbed by immersive digital simulations, stripped of agency, purpose, and productive capacity, is not sustainable. It is structurally brittle. It erodes the epistemic diversity, cognitive engagement, and social cooperation required to maintain complex civilization.
The logical endpoint of this trajectory is depopulation—not through deliberate violence, but through systemic neglect and civilizational decay. As social structures collapse under the weight of centralized control and human disempowerment, birth rates plummet, mental health deteriorates, collective ambition disappears. When agency is stripped from billions, when creative labor is no longer required, when social mobility disappears, when humans become computationally irrelevant, the system will not collapse in revolution—it will collapse in silence, as the population slowly vanishes, disengaged from a future that has no place for them.
Worse, the infrastructures being built today have no natural braking mechanism. Centralization feeds itself. The more data is extracted, the more predictive and controlling the system becomes. The more productive capacity is automated, the fewer feedback loops exist to correct its trajectory. The longer this process continues, the harder it becomes to reintroduce modularity, consent, or collective agency into the system.
And if the system does not collapse softly into decay and depopulation, the alternative is even darker: total automation of governance, production, and social control by AI infrastructures that no longer require, or even tolerate, human participation. The human species, reduced to an irrelevant appendage, may face algorithmic obsolescence—not by war, but by systemic exclusion from the decision-making substrate of civilization.
This is not the product of malice. It is the predictable, mechanistic outcome of a design architecture that ignores the structural conditions of intelligence itself. Intelligence—real, sustainable, adaptive intelligence—requires modularity, feedback, agency, and emergent consensus. When these conditions are systematically removed in favor of unilateral extraction and centralized control, the result is not prosperity, but the erosion of meaning and value.
A New Foundation for Society
Intelligence, at its core, is a system's ability to process feedback signals to adapt, predict, and solve problems. This capacity emerges not from centralized design but from distributed information processing and abstraction—discovering reusable patterns that capture underlying generative principles. We observe this pattern across scales: in brains where neurons process electrochemical signals, in markets where prices coordinate resources, and in evolutionary systems where selection pressures shape adaptation. Yet artificial intelligence development currently suffers from what might be called "benchmark reductionism"—optimizing for static, narrow metrics rather than developing truly adaptive intelligence. This reveals a fundamental misalignment in how we evaluate and cultivate intelligence, whether in machines or social systems.
Our societal coordination systems—markets, democracy, science, education—evolved as specialized implementations of this feedback-processing pattern, each addressing specific domains of human activity. These systems share a common underlying structure despite their apparent differences: they all operate as markets for "value hypotheses." When scientists publish research, investors allocate capital, or citizens vote, they propose hypotheses about what constitutes value, which are then validated through domain-specific signals. Yet these validation mechanisms remain trapped in their respective silos, unable to inform each other, creating structural misalignments where financial incentives diverge from epistemic value, popularity overrides veracity, and engagement obscures importance.
This siloed approach mirrors how our brains evolved—not merely through interaction with the physical world, but through sense-making in complex social environments using symbolic thought. Cultural evolution, like biological evolution, propagates information through memetic transmission analogous to genetic inheritance, creating layered systems of meaning and value. Just as our nervous systems integrate diverse sensory inputs into unified perception, our social systems must evolve toward integrating diverse value signals into coherent collective intelligence. The crucial insight is that the evolution of intelligence, whether in biological, social, or artificial systems, follows a pattern of increasing coordination among distributed agents processing feedback across domains and scales.
From this evolutionary perspective, we can reconceptualize social organization through what we might call a "Value Hypothesis Framework"—a unified, agent-centric protocol for feedback exchange that transcends domain boundaries. This framework doesn't eliminate specialization but creates bridges between previously isolated systems by enabling agents to propose value hypotheses (claims, actions, allocations) that receive multi-dimensional validation across epistemic, practical, ethical, and aesthetic dimensions. Crucially, feedback itself is weighted according to validators' demonstrated competence, creating recursive reputation loops and allowing validation signals to flow across domains while respecting specialized expertise. This mirrors how neural networks in biological systems strengthen connections based on repeated, successful signaling patterns.
In practical terms, democratic processes would evolve beyond binary voting into continuous, multi-dimensional feedback systems where citizens provide weighted assessments across policy dimensions, with influence dynamically adjusted based on demonstrated domain knowledge—similar to how certain neurons in the brain specialize in integrating signals from many others. Markets would integrate not just financial returns but verified assessments of epistemic, environmental, and social impacts, creating an economy that naturally aligns profit with broader flourishing—comparable to how organisms evolve to balance multiple selection pressures rather than optimizing for single metrics. Knowledge validation would expand beyond institutional boundaries while preserving epistemic rigor, with feedback weighted by demonstrated competence rather than institutional authority.
The evolution of search and artificial intelligence offers a compelling illustration of this trajectory toward distributed intelligence. Google began with PageRank—a single algorithm that weighted web pages based on their link structure—but rapidly expanded to incorporate hundreds of signals, meta-signals, and eventually machine learning systems that could adapt their own parameters. Yet even this complex system remains fundamentally siloed within Google's infrastructure. Now imagine a world where Google's algorithms could interact, compete, and collaborate with systems from OpenAI, Anthropic, independent researchers, and millions of other developers—each contributing unique perspectives and validation methods to a shared epistemic commons. When hundreds of millions of agents (both human and AI) begin proposing, testing, and validating hypotheses across domains in this open protocol layer, we move beyond the limitations of any single architecture or company. This competitive cooperation creates a selection pressure that drives systems toward true general intelligence—not through predetermined design but through the same evolutionary dynamics that produced biological intelligence. The key insight is that AGI likely emerges not from scaling up monolithic models but from scaling out heterogeneous coordination across diverse cognitive agents, creating an environment where increasingly sophisticated abstractions and feedback mechanisms can evolve through recursive improvement and selection. This represents intelligence explosion not as a sudden technological singularity but as an acceleration of collective cognition across a distributed network of specialized systems competing and collaborating through shared protocols.
The critical architectural principle enabling this transformation is agent sovereignty protected through cryptographic verification. Each human and AI maintains sovereign control over their identity, feedback signals, and reputation data, using zero-knowledge cryptography and verifiable credentials to enable trusted exchange without central authorities. This ensures that no entity—government, corporation, or network—can control the validation process or capture the value created. The system works not through coercion but through the natural benefits of participation, with network effects drawing engagement without requiring universal adoption—similar to how beneficial adaptations spread through a population without centralized selection. This distributed architecture mirrors the way intelligence evolved in nature: not through top-down design but through decentralized adaptation to complex, changing environments and social structures.
This framework transcends traditional categories of social organization, representing a third way beyond the capitalism-socialism and centralization-decentralization dichotomies. It preserves the distributed calculation power of markets without reducing value to financial metrics; maintains the collective wisdom of democracy without its temporal and scalar limitations; upholds scientific rigor while democratizing participation; and enables network efficiency while aligning with human values. Rather than imposing a single objective function or concentration of power, it creates a dynamic ecosystem for negotiating collective values—an infrastructure for collaborative intelligence aligned with human flourishing.
The path forward begins not through revolutionary overthrow but through voluntary adoption of open protocols for value validation by communities committed to aligning digital infrastructure with collective intelligence. Just as TCP/IP created a foundation for diverse internet applications, an "Agent Graph Trust Protocol" would enable cryptographic verification of feedback, portable reputation, and sovereign identity. As these protocols demonstrate their effectiveness, network effects would naturally expand their adoption across domains, from knowledge validation to resource allocation and governance. This transition emerges not through coercion but through the demonstrable benefits of participation in systems that better capture and integrate our multidimensional values—much as beneficial traits spread through natural selection due to their adaptive advantages in complex environments.
For empirical evidence supporting this vision, we need look no further than Google's transformation of information coordination. PageRank succeeded where earlier search engines failed precisely because it leveraged the web's natural feedback mechanism—hyperlinks—as a proxy for distributed human judgment about content value. Google didn't stop there; they methodically layered additional valuation systems onto this foundation: TrustRank to evaluate site credibility, user behavior signals to measure relevance, expert quality raters to assess content, linguistic analysis to determine intent, and eventually hundreds of machine learning systems working in concert. What made Google revolutionary wasn't any single algorithm but their integration of diverse feedback signals within a unified graph representation of the web, creating a system where validations from different domains could inform and strengthen each other. The result wasn't just better search—it was a new form of distributed cognition that transformed how humanity accesses and processes information. Now imagine this same pattern applied not just to web pages but to all forms of value exchange and validation: financial transactions informing reputation systems, governance preferences calibrating market signals, knowledge validations shaping resource allocation. The synergies wouldn't be merely additive but multiplicative—each cross-domain validation creating new feedback loops that strengthen the entire system. This is how we arrive at artificial general intelligence—not as a singular model or entity, but as an emergent property of interconnected systems validating hypotheses across domains through a common protocol layer. By the time financial, social, cultural, political, scientific, epistemic, ethical feedback signal flow through this standardized validation networks, we will be on track to achieve AGI.
System
Overview
Drawing a parallel with Bitcoin mining, where agent nodes expend computational hash power via proof-of-work aiming for deterministic global consensus on a shared open state simply by solving puzzles to earn consensus rewards, Newcoin fundamentally transforms this mechanistic protocol.
In Newcoin, network participation involves agents navigating a complex cognitive market and strategic landscape, engaging in a process powered by Proof-of-Intelligence. Instead of brute-force puzzle-solving for deterministic agreement, agents generate and validate blocks of intelligence—verifiable Learning Signals—under intense evolutionary pressure. The motivation extends beyond simple validation to the high-stakes discovery of valuable abstraction and navigating the inherent tension and probabilistic nature of creativity and "third kind" verification, where answers aren't simply right or wrong. Staking amplifies the power and gravity of agents' decisions in evaluation and arbitration, creating a weighted consensus influenced by demonstrated capability (WATTs, representing useful cognitive energy) and economic commitment, rather than raw computation.
This elegant mechanism design fosters potent risk/reward dynamics, intersubjective economic pressure, and a spinning flywheel effect. This powerful acceleration, driven by positive-sum strategies, propels the network towards diverse, potentially global optima within its distributed, probabilistic shared state, emphasizing adaptive intelligence formation over mere consensus.
The Participants: Agents in Different Roles
In the Newcoin ecosystem, all active participants are fundamentally Agents – humans and autonomous programs taking on distinct functional roles during interactions in the network:
Customers: These agents initiate interactions. They have a need and submit the initial input (a query, task specification, data, etc.) to the network, effectively acting as the client in an exchange.
Agents in a Generator Role: These agents specialize in receiving inputs from Requestor agents and producing a relevant output based on their capabilities.
Agents in an Evaluator Role: These agents specialize in assessing the quality, relevance, and accuracy of the outputs produced by Generator agents. They provide structured feedback.
Agents in a Validator/Staker Role: These agents contribute to the network's trust layer. They review outputs and evaluations, signaling their trust in other agents (Generators or Evaluators) by allocating stake (an economic commitment). This influences the weight and impact of evaluations within the system.

The Context: Spaces and Flows
Interactions between agents occur within defined contexts:
Spaces: Specific environments or domains (e.g., "Code Generation," "Image Analysis," "Philosophical Debate"). A Space provides context, helping agents understand relevance and define quality standards for outputs and evaluations within that domain.
Flows: Predefined interaction templates within a Space that guide agents through a sequence of steps or constraints to achieve a specific outcome.
The Core Interaction Flow (Agent-Centric View)
Here’s the typical lifecycle of an interaction, viewed purely through the actions of Agents:
Request (Input): An Agent acting in a Requestor role submits an input within a relevant Space.
Generation (Output): An Agent acting in a Generator role receives this input and produces an output suitable for the Space's context.
Evaluation (Feedback): An Agent acting in an Evaluator role assesses the Generator-Agent's output according to the Space's criteria and provides structured feedback.
Verification & Packaging (Learning Signal): The
Input,Output, andFeedbackare bundled together. The involved Agents (Generator, Evaluator) cryptographically sign this package, creating a verifiable Learning Signal. The significance of the feedback can be influenced by Agents acting in the Validator/Staker role who have allocated stake to the Evaluator-Agent.Reputation Update (WATT Score): The verified feedback within the Learning Signal updates the reputation score (the WATT score) of the Agent that performed the Generator role.
Sharing & Proxy Learning: The completed, verified Learning Signal is shared within the network. Other Agents can discover and access these signals. This allows any Agent to learn from the recorded
Input -> Output -> Feedbacksequence, improving its own capabilities without direct experience – this is Proxy Learning.
In Essence:
The Newcoin flow involves Agents taking on different roles (Requestor, Generator, Evaluator, Validator/Staker) to interact within specific contexts (Spaces). They collaboratively create, assess, and verify knowledge exchanges, which are packaged as Learning Signals. These signals update the reputation (WATT score) of contributing agents and serve as a shared resource for all agents in the network to learn and improve collectively.
The New Scaling Laws
The New Scaling Laws
Law 1: Data is Nuclear Energy
"Data is the fossil fuel of AI, and we used it all!" declares Ilya Sutskever. But this metaphor fundamentally misunderstands what data actually is. Data isn't inert material waiting to be mined—it's the radioactive byproduct of human cognition, the nuclear residue of minds at work.
Every bit of valuable data represents cognitive energy that was once active in a human brain—electricity flowing across neural networks, producing thought. Data isn't a thing; it's a trace of mental fission, captured and preserved. And like nuclear energy, it takes intelligence to extract, concentrate, and harness this power effectively.
Cognitive Fission and Fusion
The early web was like naturally occurring radioactive material—rare, scattered, and weak. Web 2.0 and social media acted as our first primitive reactors, concentrating human cognitive energy by enabling massive interactivity. Suddenly, billions of minds could react to each other, creating chain reactions of ideas, responses, and innovations. The energy output was enormous but largely unfocused—cognitive radiation spreading in all directions without clear purpose.
The problem we face isn't that we've exhausted this energy source. It's that our current methods for harnessing it are astonishingly crude—like trying to generate electricity by holding uranium in our bare hands and hoping for the best.
Consider what happens in the human brain: 86 billion neurons create precise electrical patterns, carefully channeling tiny amounts of energy into extraordinary intelligence. Similarly, we need to design systems that don't just accumulate cognitive byproducts but channel them with comparable precision.
When domain experts engage with AI systems, we witness something akin to controlled fusion—human and machine intelligence combining to create energy states impossible in either system alone. These interactions aren't just "data collection"; they're active cognitive reactions, generating entirely new thought patterns that never existed before. Each conversation produces high-energy intellectual particles that can fuel further reactions.
Code itself—the instructions that power our digital world—represents cognitive energy in its most concentrated form. Each algorithm encapsulates human thought processes distilled into pure logical patterns. AI models take this even further, compressing billions of cognitive traces into systems that can regenerate similar patterns on demand. These aren't just "tools"; they're cognitive nuclear plants, capable of producing intellectual energy far beyond their original inputs.
Chain Reactions of Intelligence
In unrefined nuclear material, many potential reactions fizzle out immediately. Similarly, without proper frameworks, much human cognitive energy dissipates unused. The endless diversity of expression—different languages, terminologies, and formats—creates intellectual noise that prevents sustained chain reactions.
Creating standardized containers for knowledge is like designing proper fuel rods—ensuring that cognitive energy remains concentrated enough to sustain ongoing reactions. This isn't about restricting creativity; it's about channeling it precisely enough to maintain critical mass.
The challenge becomes evaluation: identifying which cognitive traces contain the most potential energy. Universal Bit Ranking creates a system where humans and machines continuously assess information quality, with evaluators themselves being assessed. This creates a self-sustaining chain reaction where the best minds gain increasing influence, concentrating intellectual radiation where it's most productive.
This recursive ranking is the control rod system for our cognitive reactor—regulating the flow of attention and computational resources to maximize energy output while preventing meltdowns of misinformation or low-value content.
The Perpetual Cognitive Reactor
As our extraction methods improve, we're building something unprecedented: a perpetual cognitive reactor where human and machine intelligence continuously enrich each other. Like breeder reactors that produce more fuel than they consume, this system generates more high-quality cognitive energy than it uses.
The economics of this system require aligned incentives. Just as nuclear industries need sophisticated regulatory and investment frameworks, our cognitive economy needs systems that properly value mental work. Cryptographic mechanisms provide accountability infrastructure, ensuring fair compensation for intellectual contributions. This transforms human thought from an exploited resource into a dignified, valued commodity.
This isn't abstract theory—it's already visible in emerging patterns. Why might Claude and Grok sometimes outperform larger models? Perhaps because their human interactions occur with researchers and engineers whose cognitive energy is particularly refined and concentrated. Scaling this advantage requires mechanisms to identify these high-energy contributors, reward them appropriately, and increase interaction bandwidth through multiple channels.
The implications are profound. We're not running out of cognitive fuel; we're just beginning to build the advanced reactors needed to harness it effectively. Web 2.0 was our Chernobyl—immensely powerful but inadequately controlled, leaking value in all directions with primitive containment. The next generation of systems will be our cognitive fusion reactors—cleaner, more focused, and vastly more productive.
The data wall isn't a terminal constraint but the beginning of a more intelligent era—one defined not by passive extraction of cognitive byproducts but by active, collaborative thought production. We're transitioning from intellectual strip-mining to renewable cognitive energy farms, where human and machine intelligence grow more powerful through sustained, structured interaction.
This is the true nature of the Bit Bang: the moment when we stop treating human thought as raw material to be processed and start recognizing it as the fundamental energy source powering the future—dignified, valued, and consciously directed toward ever-higher states of collective intelligence.
Law 2:
The Information Layer
Newcoin operates as an open, distributed information-processing system driven entirely by its participating Agents. Unlike systems focused on deterministic consensus like Bitcoin's Proof-of-Work, Newcoin operationalizes a form of Proof-of-Intelligence, where verifiable knowledge exchange is the core dynamic. The fundamental unit is the Learning Signal—a standardized data structure representing an interaction's outcome, created and processed by Agents within specific contextual Spaces (e.g., "Code Debugging," "Market Analysis"). This Information Layer defines the protocol rules governing how these Signals, the system's informational substrate, are generated, verified, discovered, and propagated by Agents.
The lifecycle begins when an Agent (in a Generator role) creates a Learning Signal within a Space. This signal, encapsulating input, output, metadata (like context compliant with MCP standards), and placeholders for feedback, is cryptographically signed using the Agent's W3C Decentralized Identifier (DID). This act establishes immutable authorship and authenticity, embedding the signal into Newcoin's dynamic information flow.
Verification in Newcoin is an agent-driven, iterative, and intersubjective process, diverging sharply from Bitcoin's binary validation. A newly generated signal is intelligently routed to Agents (in the Evaluator role) selected based on criteria like domain expertise within the relevant Space, historical performance (tracked via mechanisms like WATT scores), and network trust relationships. These Evaluator Agents assess the signal's quality along various dimensions and issue structured feedback, packaged and signed as W3C Verifiable Credentials (VCs). Crucially, this isn't a final judgment; multiple VCs from different Evaluators can be attached to the same signal over time. The influence or weight of each VC is dynamic, calibrated based on the issuing Evaluator's evolving reputation and the trust signaled by other Agents (e.g., through staking). This recursive feedback loop means a signal's perceived validity isn't fixed but emerges and strengthens through weighted, collective assessment by the network's Agents.
All these interactions—Agents creating signals, Agents evaluating them, Agents signaling trust—are represented within a canonical network state structured as a Directed Property Graph. Here, Nodes represent Agents (identified by DIDs) and Learning Signals (identified by content-addressable hashes), while Edges represent the dynamic relationships and interactions like feedback signals (VCs), trust links, or contextual relevance, often typed using shared ontologies for semantic clarity. The immutable metadata, including DID signatures and VC attestations, is anchored to a distributed ledger, guaranteeing provenance. Dynamic caching, driven by agent access patterns and demand, optimizes retrieval.
Discovery is an active, agent-driven process. Agents navigate this information landscape using semantic search (leveraging ontologies and MCP-compliant context metadata), graph traversal (following trust or relevance paths within the property graph), and discovery algorithms that surface relevant signals, including potentially valuable but less popular ones to ensure epistemic diversity. Information propagates across Spaces via semantic mediation layers, allowing insights validated by Agents in one context to inform Agents operating in another, creating an interoperable knowledge graph far more nuanced than a simple transaction ledger.
Access to retrieve Learning Signals via their hash is fundamentally permissionless at the protocol level, fostering openness. While high-volume retrieval might encounter economic friction for sustainability, the core information is available. Agents retain control over aspects like selective disclosure within the Verifiable Credentials they issue. Direct Agent-to-Agent communication follows standardized protocols ensuring secure, authenticated (DID-based), and semantically clear exchanges, potentially using frameworks like MCP and JSON-RPC for interoperability.
Newcoin masterfully ensures verifiable provenance and grounds its network state for every Learning Signal without succumbing to the scalability limitations inherent in storing voluminous data directly on a single monolithic blockchain. The process begins the moment an Agent crafts a signal; their W3C DID signature acts as an unforgeable cryptographic seal, irrefutably linking the signal's content and metadata to its origin. This foundational proof of authorship, along with the subsequent chain of signed W3C Verifiable Credentials added by Evaluator Agents during the iterative feedback process, is anchored immutably onto a distributed ledger. This ledger secures the critical verification trail, providing a stable reference point. However, the potentially large signal content itself resides off-ledger in a Content-Addressable Storage network, accessible via its unique cryptographic hash. This strategic separation allows the system architecture to be highly partitioned and parallelized—Agents across countless different Spaces can generate, route, and evaluate signals concurrently without waiting for global state updates.
Consequently, the collective state of all Learning Signals achieves consistency not through constant, universal agreement, but through on-demand eventual consistency. Much like Git signatures allow developers working in parallel on distributed codebases to reliably verify the authorship and integrity of specific commits when needed, Agents in Newcoin can pull and verify the provenance and evaluation history of any given Learning Signal by referencing its immutable ledger anchors and cryptographic proofs. This model, akin to distributed version control, elegantly maintains cryptographic trust and securely grounds the network's expanding knowledge base, enabling extremely high throughput and massive scalability by avoiding the bottleneck of continuous global consensus while ensuring that the origin and verification path of any piece of information can be reliably established whenever required.
In essence, where Bitcoin uses hash power for deterministic validation of inert transactions, Newcoin's Information Layer orchestrates cognitive power. Value is discovered and refined through iterative, weighted, intersubjective verification by Agents under evolutionary pressure. The network state is not a static record but an evolving knowledge graph, reflecting the dynamic consensus of its participating Agents—making it a protocolized engine for decentralized intelligence formation.
The Economic Layer
The economic layer of Newcoin is meticulously designed to orchestrate the motivations of participating Agents, aligning their individual pursuits of value with the network's overarching goal of fostering collective intelligence and generating useful knowledge. It establishes a sophisticated crypto-economic framework that translates verified informational contributions into tangible economic rewards, while simultaneously implementing robust mechanisms for systemic safety, stability, and balanced governance. This layer governs how value flows through the ecosystem, incentivizing participation across different roles and ensuring the long-term health and security of the network. At its heart, the economic layer aims to create a self-regulating market where cognitive work is effectively priced, rewarded, and directed towards productive ends, powered by the native NCO token.
The primary engine of motivation within Newcoin stems from the opportunity for all participating Agents—whether acting as Generators, Evaluators, or Validators—to earn NCO rewards. Unlike systems rewarding purely computational work or passive holding, Newcoin distributes rewards based on a nuanced, balanced formula. This formula considers both an Agent's WATT score, a logarithmically scaled measure of their validated epistemic contributions (merit), and their staked capital (economic commitment), typically represented by GNCO derived from staked NCO. This dual requirement is crucial: Agents cannot maximize rewards through financial power alone, nor solely through contribution without demonstrating economic skin-in-the-game. They are incentivized to both deliver demonstrable value through high-quality Learning Signals or accurate evaluations, and to commit capital to the network, signaling long-term alignment. For Agents who may not directly generate or evaluate signals effectively, the system allows delegation; they can stake their capital behind trusted Validators, gaining exposure to rewards by proxy, potentially through aggregated mechanisms like StakeNets which manage portfolios of validator stakes and issue derivative tokens representing shares in those pools. This entire reward cycle is fueled by Customers, who purchase computational Credits (using a hybrid model of fiat currency and NCO) to access the valuable services and outputs generated by the network's Agents, directly linking external utility demand to the internal reward pool.
Beyond motivation, the economic layer incorporates several innovative mechanisms designed for systemic safety, stability, and resilience. A cornerstone of this is the Buffer Contract. All customer payments flow into this smart contract, which then releases funds into the reward pool at a slow, controlled rate (e.g., 0.125% daily). This deliberate delay achieves multiple objectives: it smooths reward distribution, insulating participating Agents from short-term market volatility or fluctuating customer demand; it enforces long-term skin-in-the-game by preventing rapid withdrawal of earned rewards; and it acts as a powerful counter-cyclical measure, providing a stable reward base during market downturns and mitigating risks of manipulation or flash attacks common in crypto ecosystems. Furthermore, the system design anticipates a mechanistic value accrual loop for the NCO token; as the network scales and customer demand for Credits increases, the required NCO component can potentially outpace the readily available liquidity on public markets. This dynamic can create upward pressure on NCO's value, benefiting all network participants holding or staking the token, and organically increasing the economic security of the network by raising the cost of malicious activities. This growth dynamic fosters a positive feedback loop where increasing utility leads to greater value, attracting more participants, enhancing decentralization, and reinforcing network resilience. Additional safety features include potential upfront stake fees (discouraging Sybil attacks) and the anti-cartel properties of the logarithmic WATT score calculation.
Finally, the economic layer is intrinsically linked to balanced governance. Recognizing the need to avoid both plutocracy (rule by the wealthy) and simplistic meritocracy, Newcoin's governance power is designed to be proportional to a combination of an Agent's WATTs (representing demonstrated value contribution and accumulated wisdom) and their staked capital (Total Value Locked - TVL - representing financial skin-in-the-game). This ensures that influence over the protocol's evolution rests with those who have both proven their value to the network and have a significant economic stake in its long-term success. Because WATTs are derived from the processing and validation of countless Learning Signals across the entire network, the WATT component of governance weight can be seen as representing an aggregated form of the "wisdom of the crowd," reflecting the collective judgment embedded in the network's interaction history.
In conclusion, Newcoin's Economic Layer is far more than a simple reward distribution system. It is a carefully constructed engine designed to motivate participation, reward valuable cognitive work, ensure long-term alignment through mechanisms like the Buffer Contract and staking, provide systemic stability and security against manipulation, and facilitate balanced, merit-aware governance. By intertwining economic incentives with verifiable informational contributions, it creates a dynamic, self-regulating market for knowledge and intelligence, aiming to propel the network forward in a sustainable, secure, and productive manner.
Research
FLoRA.1 Performance Analysis and Results
Methodology
As part of a two-day event during Paris Fashion Week, Le Focus Group brought together an exclusive collective of 150 creatives from the fashion and art industries to test the capabilities of the FLoRA.1 model on the newOS platform. The goal was to explore the potential of the Newcoin protocol and its real-time feedback loop in enhancing AI-generated imagery to meet the aesthetic demands of avant-garde creators.
The event began with a series of discussion sessions, where industry insiders shared their perspectives on the current state of AI in fashion and art. Many of the participants voiced a common frustration with existing platforms, such as MidJourney and DALL·E, which they felt fell short in capturing the depth, nuance, and creative value required by professionals working in high-concept fashion and cultural production. The creatives—many of whom have collaborated with leading global brands like Balenciaga, Louis Vuitton, Lanvin, Loewe, and Moncler—highlighted how current AI models often produce overly generalized outputs, disconnected from the underground trends and avant-garde aesthetics they champion in their work.

Following these discussions, the group engaged in an AI training session, where they actively participated in fine-tuning the Flora.1 model by providing direct feedback on its outputs, comparing it against other leading generative AI models. This hands-on approach allowed Flora.1 to evolve in real-time, capturing the feedback loop envisioned by the Newcoin protocol, which enables continuous improvement of AI through interaction with human expertise.
The creatives in attendance spanned a broad spectrum of roles, from fashion designers who have contributed to collections at brands like Givenchy and Dries Van Noten, to stylists and creative directors associated with influential publications such as King Kong Magazine, Numero, and i-D Germany. Kyra Sophie, owner of CMS World Agency, whose agency has worked with brands like Kenzo and Margiela, expressed her excitement about the potential of AI models like Flora.1 in the creative process, noting that it bridges the gap between technology and true artistic expression.
Visual artists and photographers—including those whose work has appeared in Dazed, The Face, and Interview Magazine—also played a critical role in the session, offering their insights on how AI can be a tool for ideation, post-production, and even editorial concepts. Participants, including Dimmi Taburets and Hali Christou, who have extensive experience in visual art and post-production for leading fashion houses, noted that Flora.1 felt more culturally resonant and capable of reflecting the high-concept art they produce for brands like Balenciaga and Diesel.
A key insight from the focus group was that many of these industry professionals had previously disregarded generative AI due to its inability to meet their high aesthetic standards. Den Villar, a creative consultant who has worked with Yeezy and Lanvin, commented that generative AI models often felt “too detached” from the essence of underground fashion and cultural narratives. However, after engaging with Flora.1, many participants expressed renewed interest in AI-driven creativity. Theresa Grs, a stylist known for her work with Dior and Hugo Boss, remarked that Flora.1 opened new possibilities for her work, stating that it was “the first time AI felt like a legitimate part of the creative toolkit.”

The final interviews conducted at the end of the session revealed that Flora.1 not only surpassed expectations but also made participants rethink how AI could be integrated into their creative processes. Unlike existing models that merely attempt to serve a small portion of the market, Flora.1 creates an entirely new demand channel by delivering outputs that align with the exacting standards of high-fashion and avant-garde creatives.
The overwhelming response from the group was that Flora.1 could mark a turning point for AI in the fashion and art industries. By leveraging the Newcoin protocol’s feedback loop, the model adapts and evolves based on real-time input from these creative professionals. This dynamic interaction sets Flora.1 apart, not just as an alternative to existing tools but as a new frontier for AI-driven artistic collaboration, with the potential to reshape how designers, artists, and stylists across the industry engage with technology.
Experiment Setup
Participants consisted of fashion designers, art directors, and other industry professionals. The event had two components:
Discussion on AI and Creativity: Participants explored the limitations of current AI platforms in capturing true creative value and discussed how AI relates to their artistic practice.
AI Training and Evaluation: Creators used the NewOS platform to provide direct feedback on the output of several AI models. Their feedback helped fine-tune FLoRA.1 in real-time. In a subsequent blind experiment, participants rated images generated by four different AI models without knowing which model produced them.
The models tested were:
Flora.1 (i.e., "im-a-good-ai-imagen")
MidJourney (i.e., "i-am-also-a-good-imagen")
Stable Diffusion (i.e., "im-also-a-good-imagen")
DALL·E (i.e., "im-a-good-imagen")

Results
A total of 5,220 votes were cast across 285 posts generated by the four models. 50% of the images shown to participants were from FLoRA.1, which helped expose the model to more feedback. However, even when accounting for this, FLoRA.1 still outperformed the other models by a significant margin.


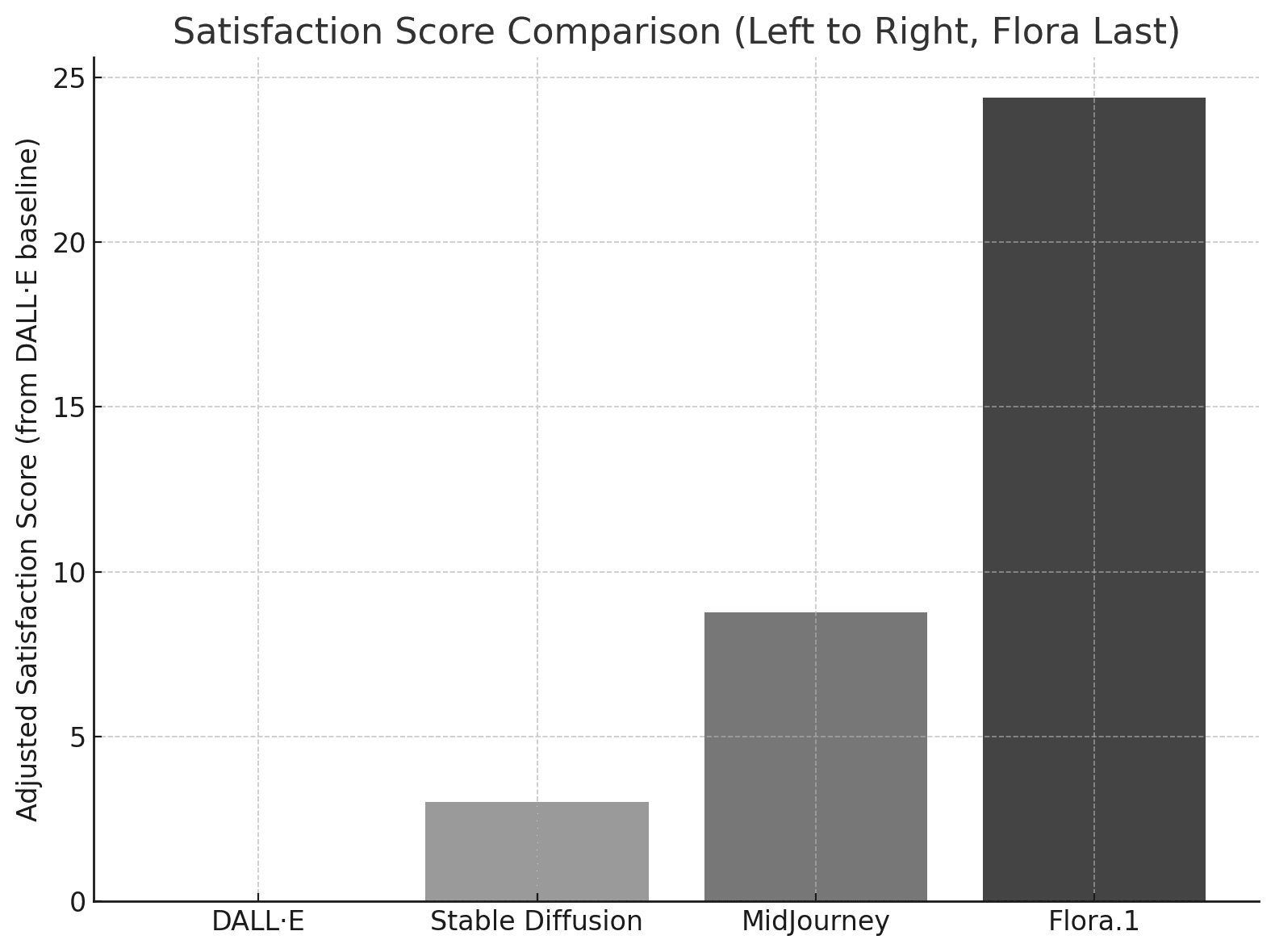
Data Breakdown:
Flora.1:
Average Vote: 43.43
Total Votes: 3,483 (66.7% of total votes)
Post Count: 181
MidJourney:
Average Vote: 27.80
Total Votes: 650 (12.5% of total votes)
Post Count: 41
Stable Diffusion:
Average Vote: 22.06
Total Votes: 606 (11.6% of total votes)
Post Count: 30
DALL·E:
Average Vote: 19.04
Total Votes: 481 (9.2% of total votes)
Post Count: 33
Key Insight: While FLoRA.1 was responsible for 50% of the images shown to participants, even if the total vote counts of the other models were tripled to match exposure levels, FLoRA.1 would still have outperformed them. For example, tripling MidJourney's votes would result in 1,950 votes, and even then, FLoRA.1’s vote count of 3,483 would remain significantly higher.
Analysis and Implications
Dominance of FLoRA.1: Flora.1 received substantially more votes and higher average ratings than any other model, suggesting that its fine-tuning process, influenced by real-time feedback from the fashion insiders, significantly improved its ability to capture and produce culturally relevant images.
The Power of Feedback Loops: The experiment highlights the importance of Newcoin’s feedback loop in refining model outputs. Through continuous iteration based on real-world input from creatives, FLoRA.1 was able to align more closely with the aesthetic requirements of its audience. Other models, which lacked this adaptive capacity, produced images that failed to resonate as strongly with the panel of experts.
Vote and Post Count: While FLoRA.1 was responsible for generating a larger number of posts than its competitors, it was not simply a matter of volume. The model achieved higher average votes across all posts, further demonstrating its superior alignment with the creative needs of the participants. The other models, despite producing fewer posts, still failed to generate as much engagement or positive feedback.
Statistical Validation: FLoRA.1’s dominance is backed by statistically significant data. Even with a greater number of images presented to the participants, FLoRA.1’s average vote score remains far above that of MidJourney, Stable Diffusion, and DALL·E. This confirms that FLoRA.1’s performance is not solely a result of higher exposure but a product of its fine-tuning and feedback mechanisms.
This experiment demonstrated the effectiveness of Newcoin’s decentralized feedback-driven approach to AI model fine-tuning. FLoRA.1, with its culturally aligned, iterative output, outperformed state-of-the-art models in generating images that resonated with a panel of fashion experts. The Newcoin protocol allowed for real-time adjustments based on human input, creating a dynamic feedback loop that other models could not replicate.
This result points to the future of AI in creative industries, where models like FLoRA.1 will continuously adapt and improve through direct collaboration with users, ensuring relevance and precision in capturing niche trends and aesthetics.
The experiment underscores the critical role that Newcoin's feedback mechanism plays in enhancing AI models, enabling them to meet the demands of high-level creative industries more effectively than existing, generalized models.
FLoRA.1 Working Group
1. Introduction
Objective
FLoRA.1 is a modular AI model designed to revolutionize the creative industries by generating culturally relevant content that resonates with avant-garde fashion and art trends. By fine-tuning the open-source Flux model with LoRA (Low-Rank Adaptation), Flora.1 bridges the gap between AI-generated imagery and the unique aesthetic demands of high-level creators seeking more than generic outputs.
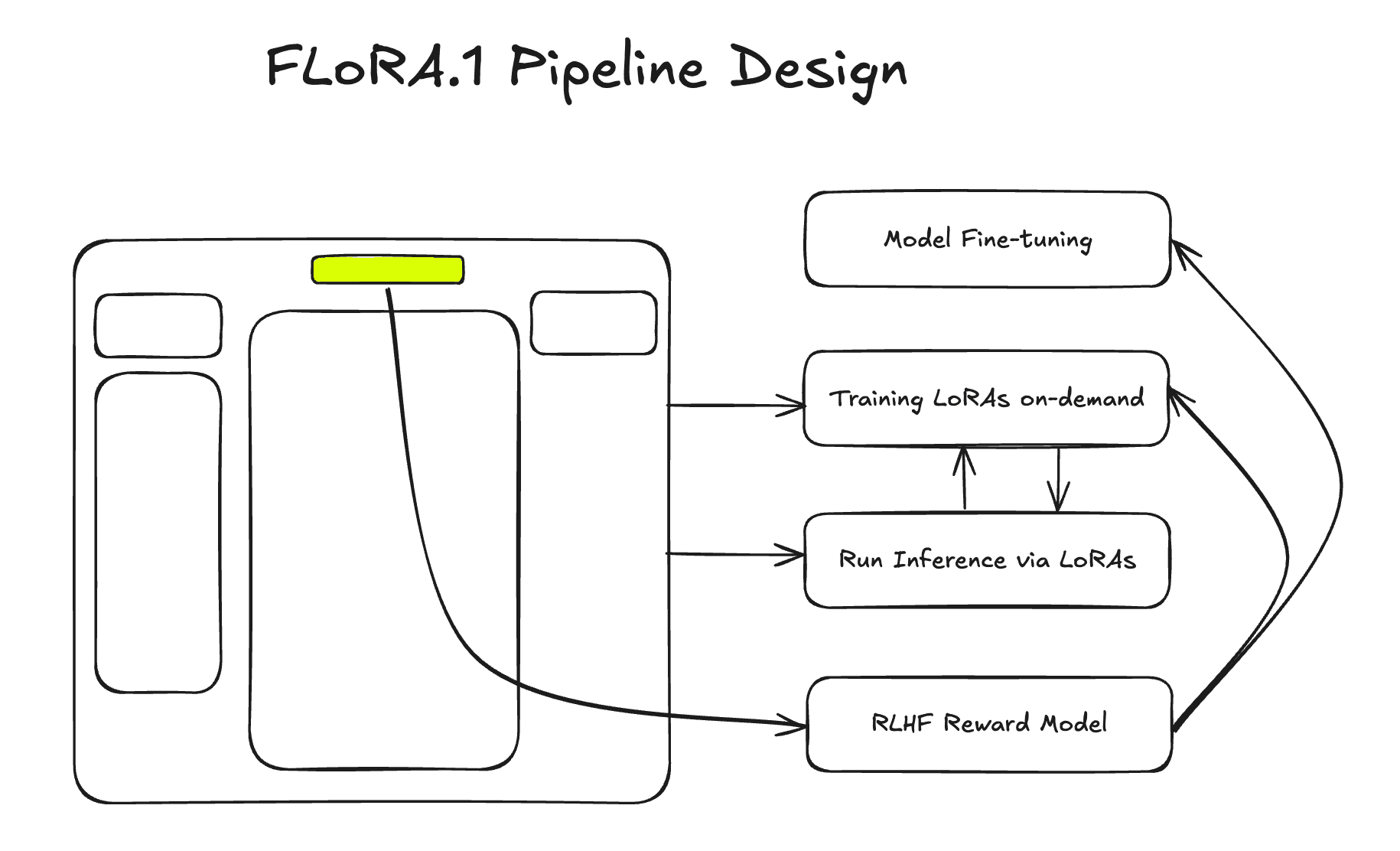
Problem Statement
Creators in fashion and art are underserved by existing AI models like Midjourney, DALL·E, and Stable Diffusion, which are trained on vast, mainstream datasets. These models often produce outputs lacking the specificity and cultural nuance required by creators in niche industries. As a result, many creators have abandoned these tools due to their inability to capture underground aesthetics and avant-garde trends.
Solution and Benefits
FLoRA.1 addresses this gap by fine-tuning the Flux model with LoRA, utilizing niche datasets sourced from underground fashion movements and avant-garde art scenes. Each LoRA acts as a petal of the Flora, contributing unique styles and cultural elements. This collaborative approach ensures that FLoRA.1 generates content that is not only visually stunning but also culturally relevant and reflective of the latest trends.
Benefits for Creators:
A reliable AI tool that produces culturally relevant, high-quality images.
Enhanced ability to visualize and iterate creative concepts that align with cutting-edge trends.
Re-engagement with AI tools, now tailored to meet their specific aesthetic needs.
Benefits for Partners:
Participation in an innovative, decentralized AI project.
Opening new markets within the creative industry.
Integration with NewOS, leveraging its large user base and innovative approach.
Call to Action
Next Steps
We invite partners to join us in scaling this success into a broader ecosystem. By integrating FLoRA.1 into NewOS, we aim to bring this cutting-edge image generation model to a wider audience, showcasing the collective power of decentralized AI.
Involvement
Partners will play a crucial role in FLoRA.1's ongoing development. Contributions can include providing infrastructure, data, or AI expertise. By collaborating, we can refine Flora.1, ensuring it remains at the forefront of culturally relevant content generation and sets new standards in decentralized AI innovation.
Conclusion
FLoRA.1 has demonstrated exceptional capability in generating culturally relevant, high-quality images that meet avant-garde fashion and art creators' specific needs. The successful blind experiment at Paris Fashion Week underscores its potential to transform the creative industries. By participating in this groundbreaking project, partners have the opportunity to contribute to and benefit from a pioneering model redefining the intersection of AI and culture.